DisCo
Disentangled Implicit Content and Rhythm Learning for Diverse Co-Speech Gesture Synthesis
ACMMM 2022
1The University of Tokyo 2Digital Human Lab, HuaWei Technologies 3Keio University
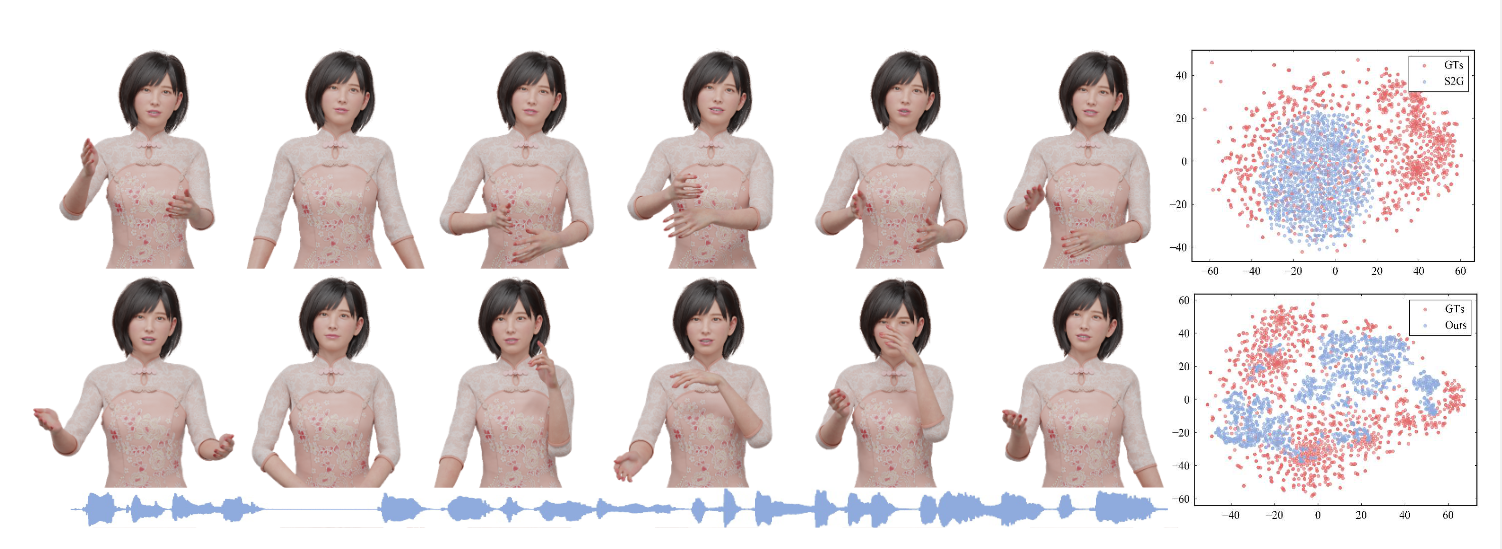
DisCo is a framework for co-speech gestures synthesis in a disentangled manner, which generates more diverse gestures without sacrificing speech-motion synchrony. Left: the input speech (bottom), generated body and hands motion by S2G (top) and Ours (middle). Right: T-SNE results for motion segments on Trinity test data.
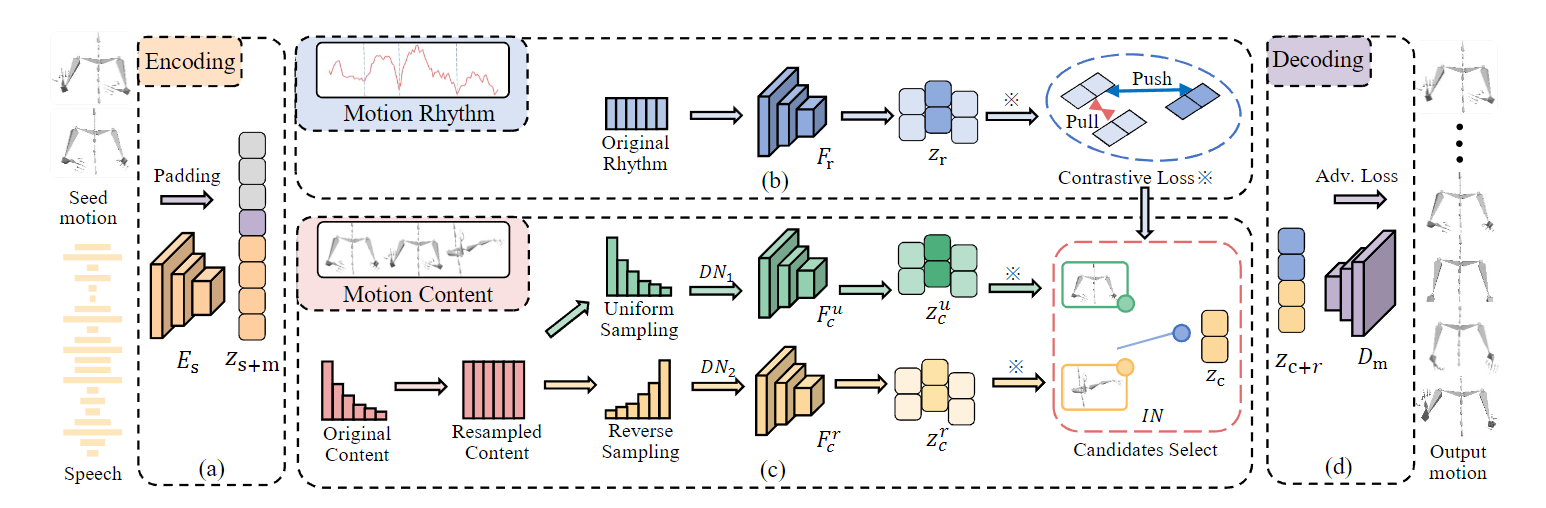
We disentangles motion into implicit content and rhythm features by contrastive loss on both branches. Afterwards, features are learned through different branches with different sampling strategies. a). Input speech is encoded and concatenated with the seed motion. b). Rhythm features learning with original distribution. Contrastive loss disentangles features by pushing and pulling the distance between negative and positive samples. c). Content branch first generates feature candidates through diversity networks, which consist of two sub-network and adopt uniform and reverse sampling. Then selects the candidates are based on rhythm feature by the inclusion network. d). Motion decoder takes rhythm and selected content features jointly with adversarial training to synthesize the final motion.

Subjective Comparisons. Each sub-figure summarizes the 40s generation motion from Trinity dataset sequence 30, our method generates more diverse gestures comparing with previous methods.
Paper Overview
Current co-speech gestures synthesis methods struggle with generating diverse motions and typically collapse to single or few frequent motion sequences, which are trained on original data distribution with customized models and strategies. We tackle this problem by temporally clustering motion sequences into content and rhythm segments and then training on content-balanced data distribution. In particular, by clustering motion sequences, we have observed for each rhythm pattern, some motions appear frequently, while others appear less. This imbalance results in the difficulty of generating low frequent occurrence motions and it cannot be easily solved by resampling, due to the inherent many-to-many mapping between content and rhythm. Therefore, we present DisCo, which disentangles motion into implicit content and rhythm features by contrastive loss for adopting different data balance strategies. Besides, to model the inherent mapping between content and rhythm features, we design a diversity-and-inclusion network (DIN), which firstly generates content features candidates and then selects one candidate by learned voting. Experiments on two public datasets, Trinity and S2G-Ellen, justify that DisCo generates more realistic and diverse motions than state-of-the-art methods.
Bibtex
More Thanks
The website is inspired by the template of pixelnerf. Licensed under the Non-commercial license.